Docker Networking and Linux Namespaces Deep Dive
This is a write up of my docker networking demo at the Docker Orlando meetup.
Let’s begin with the diagram.
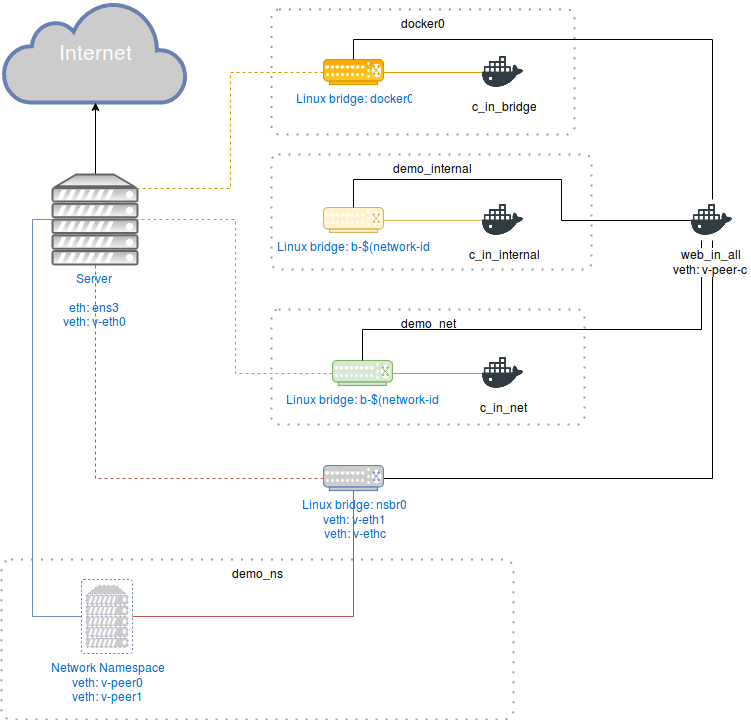 We can see in figure 1 a server which can be a physical device or a vm(cloud or not)
connected to the Internet by an interface ens3 as its gateway interface - ens3
because kvm configures it by default.
Then we have four Linux bridges. One is docker0 which is the default linux bridge
configured when Docker is set up. It has connection to the outside world, and it has
inter-container communication enabled by default. Then we have two network segments managed by Docker
which are user-defined networks. These bridges are also Linux bridges. One of these
bridges(demo_internal) is an internal network which means it doesn’t have connection to the outside, and
the other one(demo_net) has connection to the outside world. Finally, there’s
demo_ns which is only a network namespace and NOT A VIRTUAL SERVER. This
segment has two virtual ethernet interfaces which their final end are connected
to a Linux bridge nsbr0 and to the server respectively.
We can see in figure 1 a server which can be a physical device or a vm(cloud or not)
connected to the Internet by an interface ens3 as its gateway interface - ens3
because kvm configures it by default.
Then we have four Linux bridges. One is docker0 which is the default linux bridge
configured when Docker is set up. It has connection to the outside world, and it has
inter-container communication enabled by default. Then we have two network segments managed by Docker
which are user-defined networks. These bridges are also Linux bridges. One of these
bridges(demo_internal) is an internal network which means it doesn’t have connection to the outside, and
the other one(demo_net) has connection to the outside world. Finally, there’s
demo_ns which is only a network namespace and NOT A VIRTUAL SERVER. This
segment has two virtual ethernet interfaces which their final end are connected
to a Linux bridge nsbr0 and to the server respectively.
Docker0
docker0 is just a Linux bridge with no modifications whatsoever managed by the docker engine. It gives the subnet 172.17.0.0/16, so you can fire up plenty of containers to play with. An interesting observation is to see if the host’s mac address table can map as much containers as the network segment valid hosts. The docker0 is part of the docker default networks. Docker supports three types of networks: bridge(docker0), none, and host.
- Bridge is just a Linux bridge where all the containers if no network is specified
are allocated to it. The bridge network is customisable, but the docker daemon needs
to be restarted. Options of this bridge can be found in
docker network inspect bridge.
| Options | Values |
|---|---|
| com.docker.network.bridge.default_bridge | true or false |
| com.docker.network.bridge.enable_icc | true or false |
| com.docker.network.bridge.enable_ip_masquerade | true or false |
| com.docker.network.bridge.host_binding_ipv4 | ipv4 to bind |
| com.docker.network.bridge.name | bridge name |
| com.docker.network.driver.mtu | mtu |
- None disables network capabilities to containers; in other words, it’s attached to itself.
- Host adds a container on the host’s network stack.
Let’s configure the docker0 bridge. As we said previously, this is pretty much configured at installation time. But let’s take a look to the network environment before doing it.
$iptables -L -v && sudo iptables -t nat -L -v
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
$ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:43:8b:a8 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.194/24 brd 192.168.122.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe43:8ba8/64 scope link
valid_lft forever preferred_lft forever
$ip route show
default via 192.168.122.1 dev ens3
192.168.122.0/24 dev ens3 proto kernel scope link src 192.168.122.194
Iptables is accepting everything with no rules defined. Also, the routing table only shows the directly connected interface and the default gateway rule. Last, there’s only two interfaces. Let’s install docker.
$curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
$sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
$sudo apt update && sudo apt install docker-ce -y
# Output might be slightly different from yours
$sudo iptables -L -v && sudo iptables -t nat -L -v
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER-ISOLATION all -- any any anywhere anywhere
0 0 DOCKER all -- any docker0 anywhere anywhere
0 0 ACCEPT all -- any docker0 anywhere anywhere ctstate RELATED,ESTABLISHED
0 0 ACCEPT all -- docker0 !docker0 anywhere anywhere
0 0 ACCEPT all -- docker0 docker0 anywhere anywhere
Chain DOCKER (1 references)
pkts bytes target prot opt in out source destination
Chain DOCKER-ISOLATION (1 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- any any anywhere anywhere
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER all -- any any anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain OUTPUT (policy ACCEPT 2 packets, 137 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER all -- any any anywhere !localhost/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT 2 packets, 137 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- any !docker0 172.17.0.0/16 anywhere
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- docker0 any anywhere anywhere
$ip addr show
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:be:33:09:ba brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
$ip route show
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
First of all, Docker enables ip forwarding at the kernel level(echo 1 > /proc/sys/net/ipv4/ip_forward)
to have communication between internal and external hosts.In addition, it creates some
firewall rules for docker isolation to DROP or ACCEPT communication between
containers and other hosts throught the FORWARD chain.
It’s better to check this official explanation
from the docker site about container communication.
Let’s disable inter-container communication (--icc=false) and create some containers.
$sudo systemctl stop docker
$sudo dockerd --icc=false &
$docker run -itd --name=c_in_bridge busybox
$docker run -itd --name=c_in_internal busybox
$docker run -itd --name=c_in_net busybox
$docker run -itd --name=web_in_all httpd:2.4
# Inspecting iptables and interfaces after docker is installed
# Output has been cut
$sudo iptables -L FORWARD -v
$sudo iptables -t nat -L POSTROUTING
Chain POSTROUTING (policy ACCEPT 72 packets, 4997 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- any !docker0 172.17.0.0/16 anywhere
$ sudo iptables -L FORWARD -v
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER-ISOLATION all -- any any anywhere anywhere
0 0 DOCKER all -- any docker0 anywhere anywhere
0 0 ACCEPT all -- any docker0 anywhere anywhere ctstate RELATED,ESTABLISHED
0 0 ACCEPT all -- docker0 !docker0 anywhere anywhere
0 0 DROP all -- docker0 docker0 anywhere anywhere
$ip addr show
5: vethe4f578b@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 26:1f:8b:1a:7b:82 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::241f:8bff:fe1a:7b82/64 scope link
valid_lft forever preferred_lft foreve
7: veth896d794@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 3e:63:f6:3f:0e:62 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::3c63:f6ff:fe3f:e62/64 scope link
valid_lft forever preferred_lft forever
9: vethf085771@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether a6:c1:31:d7:f1:22 brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::a4c1:31ff:fed7:f122/64 scope link
valid_lft forever preferred_lft forever
11: veth690dd4c@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 6e:9a:80:a5:01:fc brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::6c9a:80ff:fea5:1fc/64 scope link
valid_lft forever preferred_lft forever
Each time a container is run with a published port(web_in_all), docker inserts
a POSTROUTING rule to nat the pusblished ports from the host to the container.
Also, notice that the rule to communicate between container has been changed from DROP to ACCEPT
when docker is run with inter-container communication disabled. Furthermore, we see
four new virtual interfaces, one for each container. Each interface is connected
to the docker0 bridge in the global namepsace, and the other end is connected to
the container network namespace; however, vethXXXXX doesn’t say anything of
which interface belongs to which container on the host. Nonetheless, the following one liner can
help you identifying the interface index, because each veth pair is created sequentially.
$DOCKER_ID=`docker ps -aqf "name=web_in_all"`
$docker inspect --format='{{.State.Pid}}' $(DOCKER_ID) | xargs -I '{}' sudo nsenter -t '{}' -n ethtool -S eth0
NIC statistics:
peer_ifindex: 11
We can verify communication in docker0
$ docker inspect -f '{{.NetworkSettings.Networks.bridge.IPAddress}}' c_in_bridge
172.17.0.3
$ docker inspect -f '{{.NetworkSettings.Networks.bridge.IPAddress}}' web_in_all
172.17.0.2
$ docker exec c_in_bridge ping 172.17.0.1 -c 2
PING 172.17.0.1 (172.17.0.1): 56 data bytes
64 bytes from 172.17.0.1: seq=0 ttl=64 time=0.604 ms
64 bytes from 172.17.0.1: seq=1 ttl=64 time=0.367 ms
$ docker exec c_in_bridge ping 172.17.0.2 -c 2
PING 172.17.0.2 (172.17.0.2): 56 data bytes
--- 172.17.0.2 ping statistics ---
2 packets transmitted, 0 packets received, 100% packet loss
$ docker exec c_in_bridge ping web_in_all -c 2
ping: bad address 'web_in_all'
$ docker exec c_in_bridge ping example.com -c 2
PING example.com (93.184.216.34): 56 data bytes
64 bytes from 93.184.216.34: seq=0 ttl=52 time=25.110 ms
64 bytes from 93.184.216.34: seq=1 ttl=52 time=31.700 ms
As docker0 is run with inter-container communication disabled, there’s no communication
between containers. Also, there’s no dns, so no resolution using other container names.
Communication to the outside world is permited.
User-defined Networks
In this doc we are not explaining about docker swarm(vxlan) at all. Please refer to the official documentation to learn more.
Docker provides something called user-defined networks which are Linux bridges with DNS resolution without having to configure your own DNS server. It has several network drivers: bridge, overlay, macvlan; and supports network plugins to build your own network driver. Also, It permits to connect several containers to different networks(including the docker0 network). As you can connect a container to several networks, its external connectivity is provided via the first non-internal network, in lexical order.
Docker has an option for linking containers in
docker0, with user-defined network I don’t see a reason to keep using it. Also, linking is not supported in user-defined networks.
Now, let’s create the docker networks.
$docker network create -o "com.docker.network.kbridge.enable_icc=false" --internal demo_internal
$docker network create demo_net
$docker network ls
NETWORK ID NAME DRIVER SCOPE
77283fff31b2 bridge bridge local
22abcb2ef140 demo_internal bridge local
119bb8423775 demo_net bridge local
e2dfddfecaaa host host local
11899b8b3162 none null local
# Inspecting iptables after creating the networks
# Output has been cut
$ sudo iptables -L -v
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER-ISOLATION all -- any any anywhere anywhere
0 0 DOCKER all -- any docker0 anywhere anywhere
0 0 ACCEPT all -- any docker0 anywhere anywhere ctstate RELATED,ESTABLISHED
0 0 ACCEPT all -- docker0 !docker0 anywhere anywhere
0 0 DOCKER all -- any br-119bb8423775 anywhere anywhere
0 0 ACCEPT all -- any br-119bb8423775 anywhere anywhere ctstate RELATED,ESTABLISHED
0 0 ACCEPT all -- br-119bb8423775 !br-119bb8423775 anywhere anywhere
0 0 ACCEPT all -- br-119bb8423775 br-119bb8423775 anywhere anywhere
0 0 ACCEPT all -- br-22abcb2ef140 br-22abcb2ef140 anywhere anywhere
0 0 DROP all -- docker0 docker0 anywhere anywhere
Chain OUTPUT (policy ACCEPT 158 packets, 19432 bytes)
pkts bytes target prot opt in out source destination
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
Chain DOCKER-ISOLATION (1 references)
pkts bytes target prot opt in out source destination
0 0 DROP all -- br-119bb8423775 docker0 anywhere anywhere
0 0 DROP all -- docker0 br-119bb8423775 anywhere anywhere
0 0 DROP all -- any br-22abcb2ef140 !172.18.0.0/16 anywhere
0 0 DROP all -- br-22abcb2ef140 any anywhere !172.18.0.0/16
0 0 RETURN all -- any any anywhere anywhere
$sudo iptables -t nat -L -v
Chain POSTROUTING (policy ACCEPT 2 packets, 138 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- any !br-119bb8423775 172.19.0.0/16 anywhere
0 0 MASQUERADE all -- any !docker0 172.17.0.0/16 anywhere
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- br-119bb8423775 any anywhere anywhere
0 0 RETURN all -- docker0 any anywhere anywhere
br-22abcb2ef140 is the bridge for demo_internal in my environment. The bridge
name follows the syntax br-$(network-id). The network id can be obtained by
docker network ls command or docker network inspect [network-name]. The same applies
for demo_net with its bridge br-119bb8423775.
We can see that two new networks has been created. Also, there’s one new rule in
the FORWARD chain, and there are two new rules in the DOCKER-ISOLATION chain.
In addition, there’s one rule added in the POSTROUTING chain and one in the DOCKER(PREROUTING) chain
for demo_net. This mean that demo_net has NAT capabilities to communicate to the outside world
,but demo_internal has not. DOCKER-ISOLATION chain isolates completely
the demo_internal network, but for docker_net means there’s no communication to the docker0 bridge. In the
FORWARD chain we see that both networks have accepted connections to communicate
between containers. In the case of demo_net it also has communication to the
outside world.
We can attach/dettach running containers to several networks. At this moment, both networks are down, because there’s now device connected to the bridge.
$ip link show
13: br-22abcb2ef140: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:0b:7a:5f:f6 brd ff:ff:ff:ff:ff:ff
15: br-119bb8423775: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:89:3b:e5:2e brd ff:ff:ff:ff:ff:ff
To connect the containers to the different networks use docker network connect [network_name] [container].
$docker network connect bridge web_in_all
$docker network connect demo_internal web_in_all
$docker network connect demo_internal c_in_internal
$docker network connect demo_net web_in_all
$docker network connect demo_net c_in_net
$docker network disconnect bridge c_in_internal
$docker network disconnect bridge c_in_internal
# Inspecting the networks
# Output has been cut
$docker network inspect bridge
[
{
"Name": "bridge",
"Id": "b04143660337bc477e4d2b420f3a799340ae2a40c9585ceb81410bf630b6a49c",
"Driver": "bridge",
"Internal": false,
"Containers": {
"270dca5b1f6715487b9b8471bdd2c1490c89defb7f311f3d5ccbd03e59687c5e": {
"Name": "web_in_all",
"EndpointID": "32147fecafb40f926d3193f4a0d61e628530b71c7c2006523e70a27d36fddfd1",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
},
"81533d0311f8d634ce84f6da6a13d0745c14a6c13150750f6563674584259175": {
"Name": "c_in_bridge",
"EndpointID": "d459ffd8177b85b5de687f5fd48e2a1b8c8b2c991af213b24f23532f64bd3ee6",
"MacAddress": "02:42:ac:11:00:05",
"IPv4Address": "172.17.0.5/16",
"IPv6Address": ""
},
},
}
]
$ docker network inspect demo_internal
[
{
"Name": "demo_internal",
"Id": "22abcb2ef14008d075290e75bf4f25463c5849617cc736c8b0196de0cabcb86f",
"Driver": "bridge",
"Internal": true,
"Attachable": false,
"Containers": {
"270dca5b1f6715487b9b8471bdd2c1490c89defb7f311f3d5ccbd03e59687c5e": {
"Name": "web_in_all",
"EndpointID": "9e22fbea0191ee648f4f4553d995fc3d10e20d821200efd01b248c77c9592c45",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
},
"56a0bb976ced986f3b7889f5dbcc5f5a3449f61b858b1857103b5c2287b5c40e": {
"Name": "c_in_internal",
"EndpointID": "1a8300e23320560e64bf984b08e98810427a88ae9b25d1c1bccce86876e3ddad",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.kbridge.enable_icc": "false"
},
}
]
$ docker network inspect demo_net
[
{
"Name": "demo_net",
"Id": "119bb8423775647a339c3c4cfbb29f30c4c99ad1e66a0606b2799c7c6bf840a4",
"Internal": false,
"Containers": {
"270dca5b1f6715487b9b8471bdd2c1490c89defb7f311f3d5ccbd03e59687c5e": {
"Name": "web_in_all",
"EndpointID": "4c69c773b612af883268b91037f2bc2280c4f01f8bb01f86b06635b479595e1e",
"MacAddress": "02:42:ac:13:00:02",
"IPv4Address": "172.19.0.2/16",
"IPv6Address": ""
},
"a9294f31b168363cd99e3ec1a4b5a125d06dabfa2422f84fcc66b57033bc556c": {
"Name": "c_in_net",
"EndpointID": "b651d1ba56524e10302a716930e6da42b1997bdd7b371a276dff6cd2fc5b5ca3",
"MacAddress": "02:42:ac:13:00:03",
"IPv4Address": "172.19.0.3/16",
"IPv6Address": ""
}
},
"Options": {},
}
]
web_in_all is the only container connected to all the networks.
$ ip route show
default via 192.168.122.1 dev ens3
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.18.0.0/16 dev br-22abcb2ef140 proto kernel scope link src 172.18.0.1
172.19.0.0/16 dev br-119bb8423775 proto kernel scope link src 172.19.0.1
192.168.122.0/24 dev ens3 proto kernel scope link src 192.168.122.194
$ ip link show
13: br-22abcb2ef140: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:0b:7a:5f:f6 brd ff:ff:ff:ff:ff:ff
15: br-119bb8423775: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:89:3b:e5:2e brd ff:ff:ff:ff:ff:ff
Both bridges now are up after we connect containers to them. There are also two rules added to the routing table as directly connected.
# Exploring demo_internal
$ docker inspect -f '{{.NetworkSettings.Networks.demo_internal.IPAddress}}' web_in_all
172.18.0.2
$ docker inspect -f '{{.NetworkSettings.Networks.demo_internal.IPAddress}}' c_in_internal
172.18.0.3
$ docker exec c_in_internal ping 172.18.0.1 -c 2
PING 172.18.0.1 (172.18.0.1): 56 data bytes
64 bytes from 172.18.0.1: seq=0 ttl=64 time=0.111 ms
64 bytes from 172.18.0.1: seq=1 ttl=64 time=0.295 ms
$ docker exec c_in_internal ping 172.18.0.3 -c 2
PING 172.18.0.3 (172.18.0.3): 56 data bytes
64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.102 ms
64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.272 ms
$ docker exec c_in_internal ping web_in_all -c 2
PING web_in_all (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.099 ms
64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.618 ms
$ docker exec c_in_internal ping example.com -c 2
ping: bad address 'example.com'
Verifying connectivity in the demo_internal network we notice connection between
container even though inter-container communication has been disabled. NICE BUG YOU
HAVE THERE DOCKER. In addition, in a user-defined network we can use the container
name just fine to communicate between containers. As demo_internal is an internal
network, there’s no connection to the outside world.
# Exploring demo_internal
$ docker inspect -f '{{.NetworkSettings.Networks.demo_net.IPAddress}}' c_in_net
172.19.0.3
$ docker inspect -f '{{.NetworkSettings.Networks.demo_net.IPAddress}}' web_in_all
172.19.0.2
$ docker exec c_in_net ping 172.19.0.1 -c 2
PING 172.19.0.1 (172.19.0.1): 56 data bytes
64 bytes from 172.19.0.1: seq=0 ttl=64 time=0.115 ms
64 bytes from 172.19.0.1: seq=1 ttl=64 time=0.269 ms
$ docker exec c_in_net ping 172.19.0.2 -c 2
PING 172.19.0.2 (172.19.0.2): 56 data bytes
64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.105 ms
64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.374 ms
$ docker exec c_in_net ping web_in_all -c 2
PING web_in_all (172.19.0.2): 56 data bytes
64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.059 ms
64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.276 ms
$ docker exec c_in_net ping example.com -c 2
PING example.com (93.184.216.34): 56 data bytes
64 bytes from 93.184.216.34: seq=0 ttl=52 time=25.192 ms
64 bytes from 93.184.216.34: seq=1 ttl=52 time=29.856 ms
Two main differences of demo_net between demo_internal. First, it has inter-container
communication enabled(so, no bug). Second, demo_net has connection to the outside world.
Network Namespaces
Provides isolation of the system resources associated with networking: network devices, IPv4 and IPv6 protocol stacks, IP routing tables, firewalls, the /proc/net directory, the /sys/class/net directory, port numbers (sockets), and so on. This means that each network namespace has its own networking stack.
It uses a virtual device(veth) pair to create a tunnel for communication between namespaces. It always comes in pair, with one end in the root namespace and the other end in a namespace.
The device is created in whatever namespace is current in. If a device does not belong to the current namespace, it becomes invisible.
In the case of docker containers, each container has their own network stack. The network namespace is located in /proc/$pid/ns/ for each process:
$DOCKER_ID=`docker ps -aqf "name=web_in_all"`
/proc/`docker inspect --format='{{.State.Pid}}' ${DOCKER_ID}`/ns/net
To configure a network namespace by hand we’ll use the ip command.
$ sudo ip netns add demo_ns
$ sudo ip netns ls
demo_ns
$mount | grep demo_ns
nsfs on /run/netns/demo_ns type nsfs (rw)
nsfs on /run/netns/demo_ns type nsfs (rw)
We have created and listed a new namespace; however, ip mounts a a virtual
filesystem named nsfs to keep demo_ns alive; otherwise, the namespace would have ended
when ip command terminated executing without mounting the network namespace.
Let’s create a veth pair device and send one of them to demo_ns
$ sudo ip link add v-eth0 type veth peer name v-peer0
$ip link show
18: v-peer0@v-eth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 26:46:1c:69:75:42 brd ff:ff:ff:ff:ff:ff
19: v-eth0@v-peer0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether aa:92:de:a0:77:a8 brd ff:ff:ff:ff:ff:ff
$sudo ip link set v-peer0 netns demo_ns
$ip link show
19: v-eth0@if18: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether aa:92:de:a0:77:a8 brd ff:ff:ff:ff:ff:ff link-netnsid 4
Notice that only v-eth0 remains in the global namespace.
$ sudo ip addr add 10.100.0.1/24 dev v-eth0
$ sudo ip link set v-eth0 up
$ sudo ip netns exec demo_ns ip addr add 10.100.0.2/24 dev v-peer0
$ sudo ip netns exec demo_ns ip link set v-peer0 up
$ sudo ip netns exec demo_ns ip link set lo up
$ sudo ip netns exec demo_ns ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
18: v-peer0@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 26:46:1c:69:75:42 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.100.2.0/24 scope global v-peer0
valid_lft forever preferred_lft forever
inet6 fe80::2446:1cff:fe69:7542/64 scope link
valid_lft forever preferred_lft forever
$ip addr show v-eth0
19: v-eth0@if18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether aa:92:de:a0:77:a8 brd ff:ff:ff:ff:ff:ff link-netnsid 4
inet 10.100.0.1/24 scope global v-eth0
valid_lft forever preferred_lft forever
inet6 fe80::a892:deff:fea0:77a8/64 scope link
valid_lft forever preferred_lft forever
$ ip route
default via 192.168.122.1 dev ens3
10.100.0.0/24 dev v-eth0 proto kernel scope link src 10.100.0.1
ip netns exec [net_ns] permits executing commands inside a network namespace.
In this case we have configure v-eth0 in the global namespace and v-peer0 inside
demo_ns. Also notice that the host creates a route for 10.100.0.0, because it’s
directed connected device. Iptables has no changes at all.
$ ping 10.100.0.2 -c 2
PING 10.100.0.2 (10.100.0.2) 56(84) bytes of data.
64 bytes from 10.100.0.2: icmp_seq=1 ttl=64 time=0.094 ms
64 bytes from 10.100.0.2: icmp_seq=2 ttl=64 time=0.057 ms
$ sudo ip netns exec demo_ns ping 10.100.0.1 -c 2
PING 10.100.0.1 (10.100.0.1) 56(84) bytes of data.
64 bytes from 10.100.0.1: icmp_seq=1 ttl=64 time=0.057 ms
64 bytes from 10.100.0.1: icmp_seq=2 ttl=64 time=0.064 ms
We have verified there’s connection inside the tunnel.
Let’s get weird
First of all, we are going to link web_in_all network namespace to /var/run/netns,
so it can be managed by the ip command.
$DOCKER_ID=`docker ps -aqf "name=web_in_all"`
$sudo ln -s /proc/`docker inspect --format='{{.State.Pid}}' ${DOCKER_ID}`/ns/net /var/run/netns/${DOCKER_ID}
$sudo ip netns ls
270dca5b1f67 (id: 0)
demo_ns (id: 4)
Then, we are going to install and configure a Linux bridge named nsbr0. This
bridge will have two veth connected to it. One is a new veth pair which one end is
going to be in the demo_ns network namespace. The other veth pair will be a
tunnel connected to the web_in_all network namespace.
$sudo apt install bridge-utils -y
$sudo ip link add v-eth1 type veth peer name v-peer-1
$sudo ip link add v-ethc type veth peer name v-peer-c
$sudo brctl addbr nsbr0
$ sudo brctl addif nsbr0 v-eth1
$ sudo brctl addif nsbr0 v-ethc
$ip link show
20: nsbr0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 26:bc:6a:17:76:9a brd ff:ff:ff:ff:ff:ff
23: v-peer-1@v-eth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6a:56:f9:8a:22:c2 brd ff:ff:ff:ff:ff:ff
24: v-eth1@v-peer-1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop master nsbr0 state DOWN mode DEFAULT group default qlen 1000
link/ether b2:9f:3c:ba:0c:97 brd ff:ff:ff:ff:ff:ff
25: v-peer-c@v-ethc: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether a6:4c:ea:4e:f0:a1 brd ff:ff:ff:ff:ff:ff
26: v-ethc@v-peer-c: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop master nsbr0 state DOWN mode DEFAULT group default qlen 1000
$sudo ip link set v-peer-c netns ${DOCKER_ID}
$sudo ip link set v-peer-1 netns demo_ns
$sudo ip link set v-eth1 up
$sudo ip link set v-ethc up
$sudo ip link set nsbr0 up
$sudo ip netns exec ${DOCKER_ID} ip link set v-peer-c up
$sudo ip netns exec ${DOCKER_ID} ip addr add 10.200.0.3/24 dev v-peer-c
$sudo ip addr add 10.200.0.1/24 dev nsbr0
$sudo ip netns exec demo_ns ip addr add 10.200.0.2/24 dev v-peer-1
$sudo ip netns exec demo_ns ip link set v-peer-1 up
After configuring our new bridge and veths devices. Let’s explore how’s the view in each network namespace:
$ip link show
20: nsbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 26:bc:6a:17:76:9a brd ff:ff:ff:ff:ff:ff
24: v-eth1@if23: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master nsbr0 state UP mode DEFAULT group default qlen 1000
link/ether b2:9f:3c:ba:0c:97 brd ff:ff:ff:ff:ff:ff link-netnsid 4
26: v-ethc@if25: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue master nsbr0 state UP mode DEFAULT group default qlen 1000
link/ether 26:bc:6a:17:76:9a brd ff:ff:ff:ff:ff:ff link-netnsid 0
$ ip route
10.200.0.0/24 dev nsbr0 proto kernel scope link src 10.200.0.1
Now we have v-eth1 and v-ethc connected to nsbr0. and ip route shows a new route
for 10.200.0.1.
$ sudo ip netns exec ${DOCKER_ID} ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
6: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
8: eth1@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
10: eth2@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
25: v-peer-c@if26: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether a6:4c:ea:4e:f0:a1 brd ff:ff:ff:ff:ff:ff link-netnsid 0
$ sudo ip netns exec ${DOCKER_ID} ip route
default via 172.17.0.1 dev eth0
10.200.0.0/24 dev v-peer-c proto kernel scope link src 10.200.0.3 linkdown
web_in_all has a new veth and a new route for 10.200.0.0.
$sudo iptables -t nat -A POSTROUTING -s 10.200.0.0/24 -o ens3 -j MASQUERADE
$sudo iptables -A FORWARD -o nsbr0 -j ACCEPT
$sudo iptables -A FORWARD -i nsbr0 -j ACCEPT
$sudo ip netns exec demo_ns ip route add default via 10.200.0.1
$ sudo ip netns exec demo_ns ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
18: v-peer0@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 26:46:1c:69:75:42 brd ff:ff:ff:ff:ff:ff link-netnsid 0
23: v-peer-1@if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 6a:56:f9:8a:22:c2 brd ff:ff:ff:ff:ff:ff link-netnsid 0
$ sudo ip netns exec demo_ns ip route
default via 10.200.0.1 dev v-peer-1
10.100.0.0/24 dev v-peer0 proto kernel scope link src 10.100.0.2
10.200.0.0/24 dev v-peer-1 proto kernel scope link src 10.200.0.2
We added a rule in the POSTROUTING chain to map demo_ns connections to nsbr0 ip address. Then,
a default route has been added to demo_ns to route connections to the outside world.
Nevertheless, which dns resolver is using demo_ns?. Remember that a network namespace
just gives a new IP stack. A dns resolver is not part of the network namespace.
Well, when you execute ip netns exec [net_ns] you are still using the global
mount namespace, so the files you are using are the same as the root filesystem.
In other words, /etc/resolv.conf is the same for all the namespaces created with
the ip netns command. However, with ip netns you might use a different resolver
creating a new file in /etc/netns/[netns_name]/resolv.conf for each network namespace.
$ echo '127.0.0.1 mytest' | sudo tee -a /etc/hosts
127.0.0.1 mytest
$ sudo ip netns exec demo_ns ping mytest -c 2
PING mytest (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.070 ms
64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.086 ms
As you can see, we hava added a new entry in /etc/hosts. Pinging from demo_ns
resulted succesful for mytest.
$sudo mkdir -p /etc/netns/demo_ns/
$echo '127.0.0.1 myns' | sudo tee -a /etc/netns/demo_ns/hosts
$ sudo ip netns exec demo_ns ping myns -c 2
PING myns (127.0.0.1) 56(84) bytes of data.
64 bytes from myns (127.0.0.1): icmp_seq=1 ttl=64 time=0.072 ms
64 bytes from myns (127.0.0.1): icmp_seq=2 ttl=64 time=0.093 m
$ sudo ip netns exec demo_ns ping mytest -c 2
ping: unknown host mytest
If we add a new resolver for the demo_ns we notice that mytest is no longer
reachable, but myns is. Just remember that /etc/netns/[netns_name]/ only works
with the ip netns command.
What about giving web_in_all exit to the outside world by nsbr0.
# Some output has been cut
$sudo ip netns exec ${DOCKER_ID} ip route add 93.184.216.34/32 via 10.200.0.1
$sudo ip netns exec ${DOCKER_ID} ip route
default via 172.17.0.1 dev eth0
10.200.0.0/24 dev v-peer-c proto kernel scope link src 10.200.0.3
93.184.216.34 via 10.200.0.1 dev v-peer-c
$sudo ip netns exec ${DOCKER_ID} ip route get 93.184.216.34
93.184.216.34 via 10.200.0.1 dev v-peer-c src 10.200.0.3
cache
$sudo ip netns exec ${DOCKER_ID} ping 93.184.216.34 -c 2
PING 93.184.216.34 (93.184.216.34) 56(84) bytes of data.
64 bytes from 93.184.216.34: icmp_seq=1 ttl=52 time=22.9 ms
64 bytes from 93.184.216.34: icmp_seq=2 ttl=52 time=33.4 ms
$sudo ip netns exec ${DOCKER_ID} ping example.com -c 2
PING example.com (93.184.216.34) 56(84) bytes of data.
64 bytes from 93.184.216.34: icmp_seq=1 ttl=52 time=53.1 ms
64 bytes from 93.184.216.34: icmp_seq=2 ttl=52 time=26.5 ms
We added a static route for example.com and we verified that is using nsbr0
as their gateway with ip route get command.
which resolver is using web_in_all? As it uses its own mount namespace, it uses
the resolver configured by docker, but you can use a different resolver if you connect
to the web_in_all network namespace using ip netns command and follow correct
network configurations.
Conclusion
- It’s better to use user-defined networks to segment, organize and isolate containers.
- You still can find bugs in Docker, some of them can be confusing.
- Network namespace provides isolation for network resources.
- Network namespace is used not only by Docker, but is fundamental in kubernetes, openstack and many others.
Bibliography
[1] http://stackoverflow.com/a/34497614/3621080
[2] https://github.com/moby/moby/issues/20224
[3] namespaces(7)
[4] https://github.com/torvalds/linux/blob/master/fs/nsfs.c
[5] ip-netns(8)
[6] ip-route(8)